


Ask any data scientist,expert or CEO in the field and he/she will tell you data quality is paramount to running a data driven business efficiently. Still in a recent survey over 60% of businesses suffer from poor data quality with that number getting even higher to enterprises with limited data governance .
But what exactly is data quality and how it affects model/forecasting/training performance. In layman’s terms good data quality means minimal loss of information needed to complete a task or making a decision. To quantify this, a number of metrics can be evaluated and currently they do include :
- Consistency
- Accuracy
- Completeness
- Auditability
- Orderliness
- Uniqueness
- Timeliness
The table below takes the case of customer data with quantifiable results while measuring these data quality attributes. Although this is a customer data example, data quality can be applied to any data source being structured or unstructured .
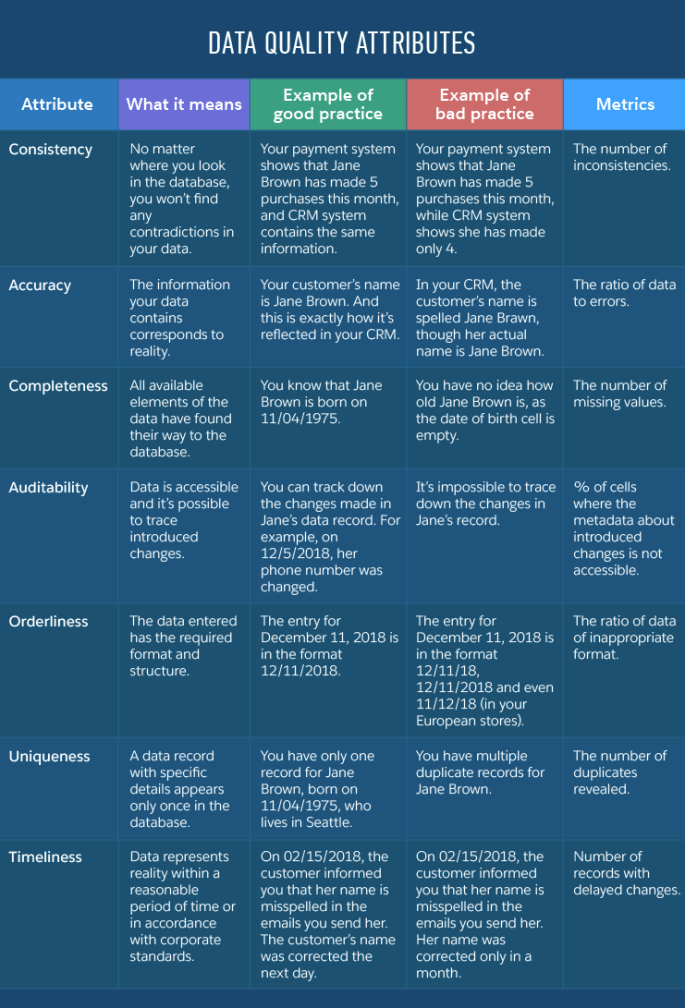
Having applied these kind of metrics to those attributes , we can have a good of idea the quality of our data set/source and can take steps to improve it. In a paper I am currently writing about this exact quantification of these metrics I examine the categorization of data quality into tiers for evaluating datasets. Depending of the dataset in question the importance of each of those factors can differ and can affect data quality in a variable way.
A data quality Tier system can look something like this with the end result a score that characterizes the data set:
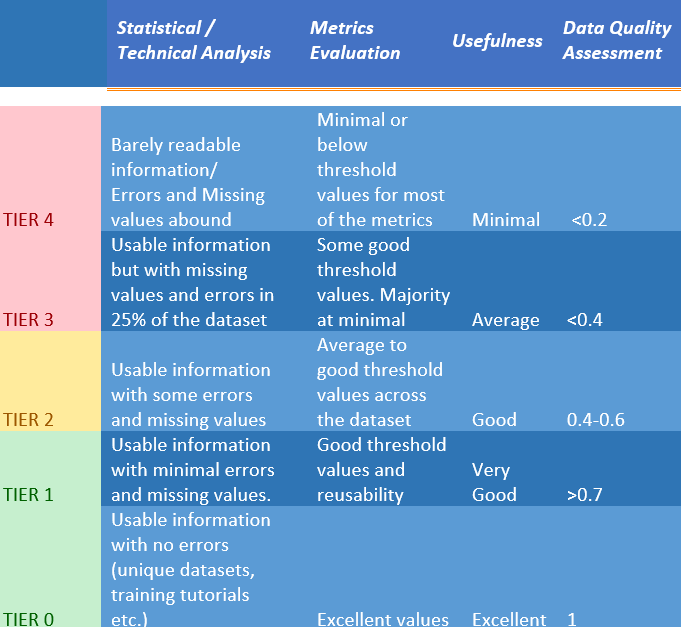
In the next blog post we will discuss how to improve data quality given our analysis.
